
Keeping Tests Valuable: Write Good Test Cases!
Writing tests without a plan is like navigating without a compass; you may reach the destination, but the path will be much more difficult.


Writing tests is a daily activity for many developers. But not all tests are created equal, and many times we are not able to write all the possible scenarios. Poorly written test cases can lead to false positives, false negatives, and an overall decrease in the effectiveness of testing efforts. We can add that many bugs go undetected because of a lack of understanding of the domain, requirements, and planning. All this can make the activity of writing tests seem futile. Let's explore some best practices for writing good test cases and tips on how to apply them. Let's start by talking a little bit about the importance of solidly understanding the requirements of a feature.
📌 Understand deeply the requirements 🤓
Usually, we developers are more into the technical side of things. We spend hours planning how a component, API, or class will integrate into the system, in which use case the functionality fits, the answer the API will deliver to the front end, execution, design, and many other questions. And this is essential. But usually, the more we think only about the technical side, the more we end up defining our point of view of the functionality being developed and forgetting to read and understand what is being requested. What do I mean by this? We can get so focused on the technical aspects of the development process that we lose sight of the ultimate goal - to deliver software that meets the users' needs. When we start thinking about how to develop a feature, we can inadvertently start defining our point of view of the functionality being developed, which can lead to misunderstandings. For example, going out developing the functionality without understanding what is being asked for in-depth can be compared to a chef preparing a dish without following a recipe or understanding the ingredients he is using. Similarly, a developer who does not understand the requirements in depth and the impact can end up delivering functionality that does not meet the users' needs.
Okay, but how does this affect testing? When we do not fully understand a requested feature, we are not able to write effective unit tests that cover all possible scenarios. The tests may cover only the features that the developers consider important and not the ones that the user needs. This can lead to gaps in test coverage and can result in bugs and problems that go undetected until the later stages of development. Also, not understanding requirements can lead to tests that are too brittle or too dependent on implementation details. For example, if a developer does not understand the expected behavior of a particular feature, he may write tests that are too specific to the current implementation. This can result in tests that fail when the implementation changes.
An analogy that can be used to explain this is building a house without understanding the initial blueprint and what the customer wants. Imagine an engineer who starts building a house without fully understanding the plans. This engineer relies only on his understanding and professional experiences to measure each room in the house, he rarely looks at the blueprint that contains the actual measurements and information on how each room should be built. What will happen when the work is finished and he hands over the house? The result may be a house that does not meet the client's needs, lacks essential features, or has serious flaws.
Bringing the analogy to the software context, this is what will happen with our testing. We won't be able to write good test cases if we only know the happy path of functionality. We need to go further! It is also essential to be in sync with what the customer needs. So if the functionality has many rules, don't think that you can solve and understand everything by yourself. Talk to the team or a QA, we can learn a lot about business rules from QA! It is in these moments that we need to clarify doubts and handwrite if necessary how the customer sees the functionality. Aligning expectations can greatly help in writing test cases that care about covering all possibilities. Why? When expectations are aligned, you can focus on writing test cases that cover all possible scenarios, ensuring that functionality is fully tested against the requirements that have been refined. For example, if stakeholders expect the software to handle certain types of user input in a specific way, developers can write test cases to ensure that the software behaves as expected. Having written test cases covering these scenarios conveys confidence to the team and the customer.
📌 Start with small steps
It is not very difficult to see developers initiating unit tests based on code. I used to do this a lot myself. I always based my tests on the implementation code, checked which part of the code I wanted to test, and started testing the happy way (probably because it covered parts of the code faster). The way I was testing was terrible and just wasted time. This started to sound like a warning to me, something was not right and needed urgent improvement! So what helped me a lot to improve the way I wrote the test cases was to think in small steps and start with invalid entries. What do you mean by this? The idea is to divide and conquer, where we have small steps with tests. We separate a set of tests that are in the same group, that are related, for example, we need to test the same string with various combinations of different invalid inputs and so on. The idea is to break a complex test scenario into smaller and simpler parts, making it easier to identify and correct errors. Ok, but how can we do this? First, the key is to understand the behaviors expected by the client, both valid and invalid. We can write these behaviors. It is important to write test cases before you type any test lines in practice, this helps you mentally visualize the behavior you want to put to the test.
Suggestion: Always try to write test cases for error scenarios and with invalid inputs first. Why? Because the happy path to test behavior you already know! What is still uncertain are the possible input actions that the user can enter. Starting testing from the cases where your code should return error messages or even throw exceptions helps to ensure that the code behaves correctly in all cases, not just the happy path. Should any unexpected behavior occur, you can more quickly detect these scenarios.
To be clear, let's take a slightly more practical example. Imagine you are working on an e-commerce discount coupon management system, and the sales analysts want to create custom coupons, i.e. functionality that will allow sellers to register (create) new coupons. You create the class and the entire validation flow following the rules that have been determined by the sales team. How can we write test cases to validate that the code has the expected behavior? The first tip is to have a small roadmap. Let's look at small didactic examples:
Step 1: Invalid Code Coupon (string)
Test Case for empty string ✅
Input: "" (empty) for the coupon code, 10 for the percentage discount, 1 for the quantity, DiscountType.Percentage for the discount type, and true for the active field.
Expected Result: An error should be returned stating that the coupon code is invalid.
Test Case for maximum coupon code length cannot be greater than 10 ✅
Input: "PROMO430304" for the couponCode, 10 for the percentage discount, 1 for the quantity, DiscountType.Percentage for the discount type, and true for the active field.
Expected Result: An error should be returned stating that the coupon code is invalid because it is greater than 10.
Test Case for maximum coupon code length cannot be less than 5 ✅
Input: "PROM" (invalid coupon) for the couponCode, 10 for the percentageDiscount, 2 for the quantity, DiscountType.Percentage for the discount type, and true for the active field.
Expected Result: An error should be returned stating that the coupon code is invalid because it is less than 5.
Step 2: Invalid for Percentage Discount (int) and Value Discount (decimal) equal to 0
Test Case for discount percentage equal to 0 ✅
Input: "PROMO30" for the coupon code, 0 for the percentageDiscount, 1 for the quantity, DiscountType.Percentage for the discount type and true for the active field.
Expected Result: An error should be returned stating that the percentage discount equal to 0 is invalid.
Test Case for Value Discount (decimal) equal to 0 ✅
Input: "PROMO40" for the coupon code, 0 for the valueDiscount, 1 for the quantity, DiscountType.Value for the discount type, and true for the active field.
Expected Result: An error should be returned stating that the value discount equal to 0 is invalid.
Here we are just a simple didactic example, but a script for test scenarios can be much more complex (most of the time they are always complex). It is important to note that we start the roadmaps with entries that we consider invalid, I will comment on this shortly. But why is it helpful to have a short test roadmap for each scenario? Writing what you are going to test makes it clear what types of invalid inputs we need to check. But you can only start writing tests that way if you read and understand the requirements that the domain expert or customer has defined. It may seem tiresome to write test scenarios and then actually write the test code. This may seem unnecessary because it is a job that QA will normally perform. But our part is to make sure we deliver the features with as few bugs as possible. This makes our job easier as well as the QA team's job easier. Remember what I said about dividing and conquering? The more we divide our tests into smaller steps, the more we can gain confidence in what we are testing, as we know that our tests have a logical sequence and are based primarily on the behaviors that the customer expects from the functionality.

Starting with small steps in unit tests and the invalid cases can be advantageous for many reasons, but here are some of the benefits that I see most:
It helps to reduce and clarify what is being tested: Starting with simple tests allows you to focus on a single behavior at a time, making it easier to understand and test. This reduces the overall complexity of testing and can make it less intimidating. Obviously, it can be a challenging task trying to break these behaviors down into small tests, especially in high-complexity systems. The tip is to try to group test scenarios and break them into smaller, independent tests, looking for invalid input scenarios, and make this division explicit with well-defined, standard names for each test.
Identify errors faster: Smaller tests run faster, which means you can identify errors faster and more accurately. This allows you to resolve issues quickly and avoid creating more errors in the process.
Avoid always thinking on the happy path: When starting with invalid inputs, you will usually always try to imagine scenarios where the user might submit incorrect data, or try ways around validations and rules. When you exercise this fault-finding mindset, you are automatically forced to deeply understand the functionality you are testing and the expected behaviors.
📌 Look for unusual inputs 🔍
Identifying unusual inputs is often a challenge for developers of different experience levels, especially when dealing with complex systems. In complex software, there are many possible scenarios and combinations of inputs that can be explored but often go unnoticed due to a lack of domain knowledge or time. We can make a quick analogy. It is like a safety inspector thoroughly examining a construction site, looking for possible risks that are hidden or not very evident. If this inspector neglects important points or areas, serious accidents can occur. Furthermore, when noting down the risk points, he does not make it clear what safety equipment the employees must wear, an accident will likely happen and the employee will be left with sequelae. He must plan and put plans in place to prevent accidents from occurring in critical areas.
Similarly, when writing unit tests, developers must consider a wide variety of possible scenarios and combinations of inputs, even those that seem unusual or unlikely. This can be challenging, as we easily adapt to thinking in limited scenarios, especially when we are unfamiliar with the software domain. But it is important to reinforce critical sense again. If a method under test validates a feature that is essential to an important process in the domain, we need to be aware of possible unusual input scenarios, for example, a string with special characters, an empty string, or even a string that reaches the limit of the allowed length. Why is this important? Because just as job safety requires identifying risks and dangers that may not be obvious at first glance, writing unit tests that take into account unusual inputs is critical to identifying potential flaws in a system. We also need to think outside the box and consider a wide variety of scenarios when writing tests. I'm going to list 5 questions that we might look to ask ourselves to find unusual entries in tests:
What happens if the input is outside the range or exceeds certain boundaries?
What is the minimum and maximum input that the function can handle?
Are there extreme cases that need to be tested, such as empty or null inputs?
Are there unusual inputs that can cause unexpected behavior?
Are there extreme cases that need to be tested, such as inputs with very large or very small values?
This can help identify and prevent potential problems before they arise in the production environment. These questions can even be written down on paper so that whenever you need to analyze possible unusual entries you can refer back to them quickly. Ok, it's clear now, but what benefits? Let's list it too so it's very clear:
We think more about the expected behavior: When testing unusual inputs, we can identify whether the behavior of the functionality under test remains the same or if this will bring some kind of harm to the behavior we want to cover, if any instability occurs we know that we need to correct it as quickly as possible. This reinforces that we must always be aware of values such as NULL, an empty string or list, special characters and other types of input data that a user may enter.
Improve code quality: When testing unusual inputs, we can identify opportunities to improve code quality, such as adding additional validations that will be needed to prevent unusual inputs in the system from affecting the behavior under test or even simplifying the code logic.
The more unusual inputs we think about and test, the more security we bring to QA and production: Different scenarios that have been tested and validated create a solid defense against future regressions if the functionality is extended or given more rules.
The more you investigate unusual inputs the more you will understand and know about the domain: The business rules, classes, components, architecture, all of this is getting easier to understand because you are now looking to cover as many scenarios as possible, but this will only be possible if you dedicate time to understanding the domain (business logic).
Is it an easy task? No! It requires effort, persistence and dedication. Remember that in certain cases you will not be able to maintain this pace, but it is important to analyze each context and project in which you are allocated, so you will know how to identify scenarios and features that deserve special attention to apply everything we have just talked about.
📌 Bugs love boundaries and hide among them! 🪲
Usually, many bugs that we find are due to a lack of understanding of the functional requirements or a lack of alignment between management and the development team, among others. But many bugs are also found at the boundaries of important rules, these bugs in software are the hardest to find, especially if you don't think beyond the happy path of code. I would like an example, I will provide one, see this class:
private float CalculateFinalAverage()
{
float average1 = CalculateAverage(GradesTeacher1);
float average2 = CalculateAverage(GradesTeacher2);
if (AbsencesAboveLimit()) average1 -= 1;
float finalAverage = (average1 + average2) / 2;
if (finalAverage >= 8)
{
return finalAverage;
}
else if (finalAverage >= 7.65f && finalAverage < 8)
{
throw new Exception("New proof: New test needed to calculate the average");
}
else
{
return finalAverage;
}
The method above has several important rules and different paths it can take, see the report generated for this class:
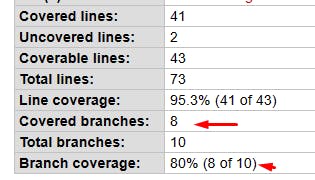
Now you may be wondering, "the number of branches to cover is not that unusual. Enterprise systems can contain more in just one method". This is true, but notice that the problem here is not just the number of branches, inputs and outputs, but exactly what we usually most ignore when writing test cases and tests themselves, see the next image:

The arrows point out the big danger and represent well the theme of this topic. The boundaries! Obviously, we need these validations, we cannot escape them. It is when we bump into boundaries that it is time to act and think of more strategies to adopt and put in place to analyze whether the boundaries hide bugs or not. So if we haven't done any of the things we've talked about in the previous topics, we're probably going to continue to have bugs and unexpected behavior in our software. So how can we write reliable test cases to verify that these boundaries are represented by <=, <, >= conform to the expected behaviors? Obviously by understanding the requirements, talking to the domain experts, and writing tests with many unusual inputs and especially those that look for the boundary of each partition. Let's look at this code:
if (finalAverage >= 8)
{
return finalAverage;
}
else if (finalAverage >= 7.65 && finalAverage < 8)
{
throw new Exception("New proof: New test needed to calculate the average");
}
else
{
return finalAverage;
}
If the finalAverage value is greater than or equal to 8, the function will return the finalAverage value. Otherwise, if the value of finalAverage is between 7.65 and 8, the function will throw an exception with the message New test needed to calculate the average, this indicates to us that the current average is not considered sufficient and that a new test is needed to obtain an average that satisfies the requirements of the institution. Finally, if the value is less than 7.65, the function will also return the finalAverage value. To clarify, if the student has an average below 7.65, according to the rules of the institution, he is automatically failed with no chance of taking a new test. Therefore, we only return the final average value for values below 7.65 or equal to and greater than 8.
But observe that in these scenarios we have many things to explore especially important boundaries! Mainly because we have the binary logical operator && (AND) that is used to check if two conditions that are to its left and its right are true at the same time. Let's write test cases for this piece of code. We can group the test cases into steps:
Step 1: Final average equal to or higher than 8
Test Case 1: Final Average equal to 8 is accepted.
Input: finalAverage = 8.0
Expected result: 8.0
Test Case 2: Final Average higher than 8 is accepted.
Input: finalAverage = 9.0
Expected result: 9.0
Test Case 3: Final Average less than 8, must fall in the else-if.
Input: finalAverage = 7.90
Expected result: Next condition is called.
Step 2: Final average less than 7.65
Test Case 4: Final average lower than 7.65.
Input: finalAverage = 7.64
Expected result: Must fall into the else statement and return directly the final average without throwing any kind of exception.
Step 3: Final Average equal to or between 7.65 and 8
Test case 5: Final average equal to 7.65 should throw a new Exception.
Input: finalAverage = 7.65
Expected result: "New test needed to calculate the average" exception thrown.
Test case 6: Final average between 7.65 and 8 should throw a new Exception.
Input: finalAverage = 7.9
Expected result: Throwing exception "New test needed to calculate the average".
The purpose of this approach and example is to demonstrate the importance of worrying about testing these limits. All the steps that have been written seek to explore values below and above, separated by clear steps and test cases for each step. The test cases should always follow the expected behavior of each defined rule, but it's important to understand what happens at the boundaries of each statement. It is important to reinforce that the more specific and critical the rules are, the more it is also necessary to evaluate if the code is still readable or if it is already time to think about refactoring and separating responsibilities.
Many developers believe that just testing the branches and covering them is enough, but unfortunately not, it is also necessary to create test cases and practical scripts for more complex rules or containing many boundaries with logical operators and equality operators. The more conditionals and logical operators an algorithm has, the higher the level of cyclomatic and cognitive complexity. The code flow becomes more and more complex. And the effect is reflected in the tests, we practically need to further refine our test cases and dive into the requirements and details of the rules. Usually, bugs are found in these details, often ignored due to a lack of knowledge in the domain, a lack understand of requirements and not looking for logic flaws in the boundaries.
To conclude this topic, it is important to explore all the possible scenarios that we encounter on logical operator boundaries, whether working with strings, floats, decimals, and doubles. Below I will list tips on how to try to put this into practice in situations that require testing and thinking about boundaries:
Testing edge scenarios: Some scenarios where boundaries exist can present higher levels of complexity than just checking values at the boundaries. For example, when a function works with dates, testing cases where year changes, daylight savings time, or leap years occur can be considered relevant.
Identify the boundaries: To design effective test cases, it is essential to identify the input boundaries that can influence the operation of the code. Constraints involve the minimum and maximum acceptable values, as well as constraints that determine changing states or behaviors.
Choose test values that cross boundaries: Choose test values that are near or at the boundaries of the identified boundaries. This includes testing values that are less than, equal to, and greater than the boundaries, and testing exact values at the boundaries. Testing these boundary values can reveal problems in logical conditions and conditional structures that are not obvious in other situations.
Logical operators should be checked: Writing good test cases that explore boundaries when the logical operators || and && are present is essential. When you see a piece of code with many logical operators working together, be suspicious and try to explore all possible scenarios for these boundaries.

The more you are objective and think about test scenarios, the more you will exercise and train this skill, it is an activity that requires mental effort and also patience to look for bugs that hide in the borders of your code.
📌 Will we always be able to write great test cases? 🧐
Writing good test cases before writing test code is like building a road. The planning phase is essential, considering all the possible obstacles, and dangers of landslides, analyzing the signs needed for each curve and determining speed limits. When the road is built with care and planning it brings more confidence to those who will drive it in the future. Likewise, when test cases are well written, considering all possible scenarios and risks, software testing and development will be more efficient and effective.
It will not always be possible to write great test cases. We also need to be realistic in saying that it is not always possible to cover all possible scenarios. However, with practice and experience, you can improve your skills in writing effective test cases. This is a process that can take years, and it requires consistency! Furthermore, collaboration and communication with other team members, such as developers, product owners, and other stakeholders, can help identify possible extreme cases and scenarios that may not be immediately obvious.
In summary, writing great test cases requires a combination of skills, experience and continuous improvement, it is a collaborative effort involving many people, not just the development team, these teams working together help ensure software quality.
Conclusion
In conclusion, keeping testing valuable is a fundamental part of quality software development. Writing good test cases not only improves the effectiveness of the testing process but also ensures that the application is reliable and efficient. By investing time and effort in creating effective test cases, you are establishing a more productive and collaborative development environment. Other developers will notice your efforts, and this is sure to serve as an example to many! By applying some of the tips we've seen in this post, your test scenarios will get better and better! Don't underestimate the power of writing good test cases, as it is an essential skill that can take your project to a new level of quality and efficiency.
I am very grateful for reading to the end. If you enjoyed it, please share, it can help other developers too! See you next post! 😉
Scientific studies on the subject, I recommend you read! 👇
How Developers Engineer Test Cases: An Observational Study - Authors: Maurício Aniche, Christoph Treude, Andy Zaidman
Books that I consider essential for everyone ✅:
Effective Software Testing: A Developer's Guide - by Mauricio Aniche
Unit Testing Principles, Practices, and Patterns - by Vladimir Khorikov