Keeping Tests Valuable: Be Careful With Regressions!
The more effective the tests are, the more security they convey to us in the fight against regressions!

Hi, I'm Rafael, but you can call me Rafa! 😄 I'm a software engineer passionate about everything that involves technology, with more than 5 years of experience in the market. Throughout my career, I worked in banking institutions, developing innovative solutions and contributing to the digital transformation of the financial sector.
With a strong interest in software architecture and testing, I am constantly looking to specialize and improve my skills in this area.
Here, you will find tips, tutorials and discussions on the most varied topics related to architecture, good practices and software testing, always with the aim of sharing knowledge and learning from other developers. I value the exchange of experiences and I am always willing to listen and learn from my professional colleagues.
Feel free to get in contact, leave your comments and share your own experiences and knowledge. Together, we can build a stronger, more collaborative community in the software development world.
Although the presence of software tests can be an indicator of quality, it is not necessarily synonymous with high-quality software! Writing tests is also a task that requires our attention to maintain the quality of the tests!
In other articles, we have commented a lot about the importance of testing and writing good unit tests. But we know that this is not an easy task. Many variables often prevent us from creating good tests. That is why the goal of this series of articles is to list the basic pillars for writing good unit tests. We will explore these pillars in detail and provide tips and examples on how to protect your software with the help of unit tests. In this article, we will talk about regressions, understand their dangers and how they usually occur, how to identify possible regressions, present some examples, and comment on the benefits of writing tests that have these essential characteristics.
Let's start by better understanding what regression is in the context of software engineering.
📍 What is regression?
I always like, before diving into any subject, to understand the origins of the subject, I usually start by understanding the meaning of the word, which in this case is regression. The word comes from the Latin "regressus", which means "to return to a previous state or place". Further researching the word in English in the dictionary, I found some interesting references that I will list below:
a situation where things get worse instead of better.
Who has never been in a situation like this? Either in personal aspects of life or at work? Now look at another interesting description for the word regression:
a return to a previous and less advanced or worse state, condition, or behavior.
Usually, when a person takes his car that has some mechanical problem to be analyzed and repaired, we always hope that the problem will be solved and the car will return to the correct and better condition. We never want the state or condition of the car to return to a worse condition. The same can be said for software! First, we have to understand that a regression in software means that a feature stopped working as planned after some modification in the code, usually after implementing a new feature. And this is something very serious! Usually, regressions are feared by everyone, especially in large corporations where the impact of an important feature stopping working can generate losses of millions! And there are two types of regression: functional and non-functional. See the differences:
Functional: This is the most common form we see and occurs when a change in the code leads to a break in a functionality that is part of the existing business solution.
Non-functional: This is a less common form of regression, and occurs when a change in the code leads to a degradation in non-functional aspects of the software, such as performance, scalability or security. For example, if a code change results in a significant increase in software latency, processing overhead, and so on.
These types of regressions can go undetected. Our focus here in this article is functional regressions. So let's talk about how unit testing can help detect regressions.
📍 What is the role of unit tests in helping to detect regressions?
We often end up underestimating the role of unit tests. But they can help a lot, especially in avoiding regressions. Let's look at some examples, first in a didactic way. Take a look at the class below:
public class Phone
{
public bool isValid(string phone)
{
if (phone == null)
{
return false;
}
if (!phone.All(char.IsDigit))
{
return false;
}
if (phone.Length < 11)
{
return false;
}
if (phone.Length > 13)
{
return false;
}
return true;
}
}
The class is quite simple and seeks to validate a phone with the criteria in the conditional structures, but we will add a new rule for the Phone class:
public class Phone
{
public bool isValid(string phone)
{
if (phone == null)
{
return false;
}
// New rule requested
if (phone.StartsWith("0"))
{
return false;
}
if (!phone.All(char.IsDigit))
{
return false;
}
if (phone.Length < 11)
{
return false;
}
if (phone.Length > 13)
{
return false;
}
return true;
}
}
The developer then runs the tests, and everything looks fine. Also, after the new check that the class performs, the developer implements a simple refactoring, see how it looks:
// I didn't add all the checks in the return to not pollute visually. Example for educational purposes only!
public class Phone
{
public bool isValid(string phone)
{
if (phone == null) return false;
if (phone.StartsWith("0")) return false;
return phone.All(char.IsDigit) && phone.Length > 11 && phone.Length < 13;
}
}
Now everything looks perfect, let's create a new test to verify that the new validation behaves as expected:
// Phone starts with 0
[Fact]
public void IsValid_PhoneStartsWith0_ReturnsFalse()
{
//Arrange
string phone = "09985154339";
var obj = new Phone();
//Act
var result = obj.isValid(phone);
//Assert
Assert.False(result);
}
Naturally, is expected to run all tests or an automation tool does this, for example after a push to the repository. But a test that was already written by another developer fails, see the test that failed:
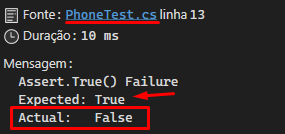
This was not what the developer expected, so he parses the failed test, sees below:
[Fact]
public void IsValid_PhoneWith11Digits_ReturnsTrue()
{
//Arrange
string phone = "19925154339";
var obj = new Phone();
//Act
var result = obj.isValid(phone);
//Assert
Assert.True(result);
}
To find the problem the easiest and perhaps quickest way is to debug, but we can do a logical exercise here. Before refactoring, each conditional structure contained its own returns. But now we have a single conditional structure with the logical && (AND) operator that appears twice!
return phone.All(char.IsDigit) && phone.Length > 11 && phone.Length < 13;
Notice one important point, if the string contains only numbers, is greater than 11 and less than 13 the return is true, but what if the string is equal to 11 and 13? The previous behavior of the code, which is the expected behavior by the client and stated in the requirements, considered a string with a length of 11 and 13 characters to be valid. But not anymore! The behavior of the class has been broken. So what does this show us? First, the unit test prevented a functionality regression!
Second, if unit tests did not exist, you would need a manual test to be able to detect this regression. Do you understand more clearly the importance of unit testing in the fight against functionality regression? If the user's phone number happened to contain 12 characters, that would be fine, and the validation would be accepted. But any other user who had a phone number with 11 or 13 characters would not have a valid phone number for the system.
With unit tests, regressions are easy to detect, bringing confidence to the developers and the QA team. Now, after the test has failed the developer can reliably detect the problem and fix the regression:
public class Phone
{
public bool isValid(string phone)
{
if (phone == null) return false;
if (phone.StartsWith("0")) return false;
// equality operator is now present
return phone.All(char.IsDigit) && phone.Length >= 11 && phone.Length <= 13;
}
}
The declared equality operator now allows a string with a length equal to 11 or 13 characters. You might be thinking, "Wouldn't this fit in as refactoring resistance?" No! In this case, the final behavior was changed, not because of the refactoring, but because of incorrect logic implemented during the refactoring process. After refactoring the observable behavior was changed because the developer did not try to make sure of the requirements. So it is clear that this is a case where the unit tests helped to detect a regression. Here is the definition of refactoring:
Refactoring means changing existing code without changing its observable behavior. The intention is to improve the non-functional characteristics of the code, such as making the code easier to read and decreasing the overall complexity of the algorithm.
Let's now understand what strategies we can adopt to improve the scope of our tests in regressions.
📍 How to increase the chances of tests revealing regressions?
This may be a deep subject, but it is important to comment on. After all, how can we increase the chances of tests revealing regressions of already existing functionality? Well, we can try to mention two strategies.
The first one that I consider essential is to identify components that are essential and are usually responsible for validating and executing rules that are critical to the system. Why? Usually, in these classes or components, a regression of functionality can mean incalculable damage to the business. In large applications that follow good practices and principles, business rules live in the domain. We can say that there are great validations and rules. One strategy to increase the chances of finding regressions is to focus on testing behaviors of these classes and components focusing on requirements. We must remember that the more code we have in a system, the more exposed we are to the risk of making changes that will regress the software to a state of unacceptable behavior, so it is important to ensure that these features are always protected with quality testing. The big problem? Usually, many developers do not have the privilege of working on systems that have an acceptable code design and architecture, and many validations are at various points in the application. I have experienced this myself. So how can we still use unit tests to avoid regressions in this scenario? A book that helped me and still helps is Martin Fowler's Refactoring Improving the Design of Existing Code, this book provides essential tips for refactoring methods, classes and components safely, and best of all, using tests!
The second strategy we can adopt is to analyze the complexity of the code. Why? When the complexity of the code increases, the chances of functionality regressions also increase. Sometimes the flow is easy to understand, but the coupling and methods with difficult and large names, make it difficult for the developer to add new functionality to an existing class, we can quickly cite other factors:
Interdependencies: In complex systems, components and code modules tend to be more interconnected and interdependent. Changes in one part of the system can cause unwanted and unexpected effects in other parts.
Difficult to understand: Complex code is more difficult to understand and analyze. This increases the likelihood that developers will introduce errors or modify parts of the code that affect existing functionality.
Code reuse: Complexity often leads to code reuse, which can be beneficial in terms of efficiency, but can also result in problems when changes in one component are propagated to other components that reuse it.
Another point to note is that the more complex the business logic becomes and with more flows, the chances of regressions also increase because it becomes more difficult for developers to understand and manage the interactions between different parts of the system. We must not forget that this also increases the probability of errors or misunderstandings occurring, leading to unintended changes in the behavior of the software. We can make a very brief analogy to make it easy to understand how critical this complexity factor is.
Think of a tangle of electrical wires, where each wire represents for us a part of the code. When the wires are well organized and identified, it is easy to trace and solve problems. However, as the tangle of wires increases in complexity, it becomes increasingly difficult to identify which wire is connected to which component. Consequently, a change in one wire is more likely to affect other components of the system in unintended ways, leading to regressions. To avoid regressions, what do electricians do? Electricians use a multimeter to check that there is a proper connection between two points in a circuit this type of test is known as continuity testing. This helps identify whether a wire is connected properly or if there is a break in the circuit. We can also point out that they try to be organized, keeping each wire as separate as possible, and they use labeling to identify different wires.

Just like electricians, we have unit tests to verify the behavior of the code, we don't need to put this tool aside. The electrician can identify faults in the electrical circuit after adding a new wire or component using testing techniques, and if we also create tests, we can avoid regressions! But it's good to stress that testing must be comprehensive and effective, only then can it help detect and correct regressions quickly, increasing software quality and reliability. And having unit tests makes regressions easier to understand because:
Focuses on expected behavior: Unit tests written with a focus on the expected behavior of the code, rather than its implementation, help identify deviations from the desired behavior, which can signal the presence of regression.
Isolation: Unit tests target specific pieces of code, isolating the functionality under test. This makes it easier to identify the root cause of regression since it is likely to be related to the code or component being tested.
Fast feedback: Unit tests provide fast feedback on the newly written behavior or new feature. When regression occurs, developers can identify it quickly and fix it before it becomes a bigger problem.
The goal of testing is to help the system grow healthily and quickly, bringing confidence and security to everyone involved. So always make a habit of creating quality tests, especially for business-critical functionality! Now let's talk about a factor that sometimes goes unnoticed, but that can also cause regressions and affect the tests, false negatives.
📍Watch out for false negatives!
False Negative means that a test case passes while the software contains the bug that the test was intended to capture.
A false negative indicates that there is no bug when there is one.
Ok, but how does this happen? Let me try to demonstrate an example with C#. Note that it is a didactic example and to try to illustrate how we can identify a false negative, I am trying my best 😁. We have in the example below a class responsible for checking if a user can access a specific resource based on their age, country and premium subscription. Let's also assume that the developer applied a refactoring of the code below:
public class AccessValidator
{
private const int AgeMinimum = 18;
public bool UserAccessResource(int age, string country, bool signaturePremium)
{
if (age < AgeMinimum) return false;
if (country == "Brazil" && signaturePremium) return true;
return false;
}
}
Before showing the refactoring note that the developer didn't pay attention and ended up introducing the wrong logical operator:
public class AccessValidator
{
private const int AgeMinimum = 18;
public bool UserAccessResource(int age, string country, bool signaturePremium)
{
return age >= AgeMinimum && country == "Brazil" || signaturePremium;
}
}
Now check out the test that was written without planning and with low attention:
using Xunit;
public class AccessValidatorTest
{
[Fact]
public void CanAccessResourceTest_FalseNegative()
{
// Arrange
var accessValidator = new AccessValidator();
int userAge = 19;
string country = "Brazil";
bool hasPremiumSubscription = false; // developer made a mistake and set false, the test should fail but it won't!
// Act
bool result = accessValidator.CanAccessResource(userAge, country, hasPremiumSubscription);
// Assert
Assert.True(result);
}
}
In this example, the test checks whether a user who is 19 years old, from Brazil and without a premium subscription can access the resource. The test will pass because the condition age >= AgeMinimum && country == "Brazil" || hasPremiumSubscription will be true. The logical operator || is the "OR" operator used to combine two boolean expressions and returns true if at least one of the expressions is true, that is, it is incorrect to use this operator in the return.
But the real requirement is that the user must be of minimum age, live in Brazil and have a premium subscription (all criteria must be met) to access the feature. In this case, the test does not reveal the problem in the code and gives a false negative.
The requirement may have been understood in the right way (or maybe not), but for some reason, the developer used the wrong logical operator. It could also be that the developer was not focused enough or was in a hurry to deliver the task and therefore wrote this meaningless unit test. This demonstrates an important point about how we should think and write many different scenarios in tests. If the developer and the team feel that this test is enough, or even not doing a code review, a bug will be passed on. What would help to detect this false negative? Written other test cases! So we cannot be satisfied with just outputs as true, we must also have outputs that consider an expected result as false, see the example below:
[Fact]
public void UserAccessResource_UserInAnotherCountry_ReturnsFalse()
{
// Arrange
int age = 25;
string country = "USA";
bool signaturePremium = true;
AccessValidator validator = new AccessValidator();
// Act
bool result = validator.UserAccessResource(age, country, signaturePremium);
// Assert
Assert.False(result); // We expect a false return, this helps to avoid regressions
}
This test was written to pass (turning green ✅) as we are expecting the return as false, after all the input USA is not valid according to the requirements. But we know that the test will turn red (🛑) and will not pass. So now we are considering other inputs and other test cases and this brings more confidence to our test suite:
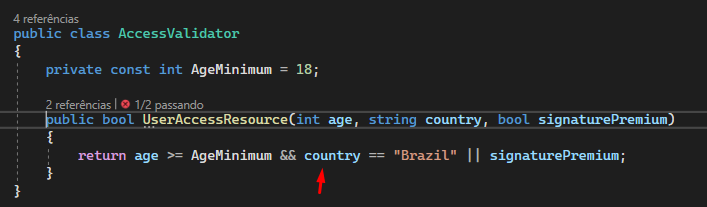
According to the current implementation of the AccessValidator class, the expression age >= AgeMinimum && country == "Brazil" || signaturePremium returns true if the user has a premium subscription, even if he is in a country other than Brazil. But the new test we just wrote with "USA" as the input country causes the UserAccessResource() method to return true even if the user does not meet all the criteria (minimum age, living in Brazil and having premium membership). This way the test will fail, as the method is expected to return false in this situation, we declare an Assert.False, which will get true as the result.
But what is the relation between regression and tests that generate false negatives? The relationship is in the ability of tests to detect problems introduced by new changes in the code. If automated tests fail to identify a regression of functionality because they always generate false negatives, this can lead to an increase in the number of bugs and problems in the software. Besides, this does not create a trust for anyone! Is it not clear? We can make another analogy. Please be patient with me 😂.
Let's separate the analogy into two steps for clarity. First, imagine that you are the coach of the team you have been supporting since childhood. Your team is performing well and all the positions work, your players get along and have good harmony. Then, to give a chance to other reserve players, you decide to make a change in the tactical scheme to make the team more in tune, adding a new player and adjusting the position of some others. The regression of functionality would be as if, after this tactical and player change, a part of your team starts to play worse than before, it could be the midfield or even the attack. Maybe the players are not getting along, or the new player is not fitting well into the tactical scheme. It seems that there has been a regression in the performance of your team, we can say that it is equivalent to the regression of functionality in software development.
But what about the false negatives? Still using the soccer team example, think that you conduct specific training to test the effectiveness of your new tactical scheme. During training, everything seems to be working perfectly. However, when it comes time for the official game, your team does not perform as well as it did in training, and gaps appear. It seems that the training sessions failed to detect these flaws, that is, there were false negatives.
Just as the coach must identify flaws in the team's performance and correct the strategies, we as software engineers must ensure that testing is effective in identifying feature regressions. If testing fails to detect these regressions because there are always false negatives, the quality of the software will suffer. False negatives allow functionality regressions to go undetected since unit tests are not capturing the problems present in the code.
This can lead to feature regressions not being identified and fixed at development time, creating problems for end users, which can lead to lower software quality and reliability.
Okay, you've said enough about the problems, what about the solution? I can list some tips, which I hope will be helpful:
Plan and write comprehensive and efficient tests, ensuring that critical functionality and boundary cases are tested. Stop writing tests in a hurry, stop writing tests without planning, it does not benefit you.
Update tests as the software evolves and its complexity increases so that they reflect changes in the code. Having tests that only cover small parts of behavior, but don't test the main features and critical functionality are practically useless.
Perform regression tests frequently, to ensure that new changes do not negatively affect the performance of the system.
Involve QA's when many questions arise. They are usually domain experts. They know many rules and are in constant contact with the customer.
Implement code review and continuous integration processes, to identify and fix bugs as early as possible. Code review is essential, where other devs can give suggestions and point out flaws, both in unit tests and in the implemented code itself.
Don't create tests that only expect positive cases or true returns as final results. Test that the behavior also fails and returns false when the rule is not fulfilled and does not conform to the requirements!
It is the role of all developers to collaborate to write tests that detect regressions! We all need to ensure that testing is effective and avoiding false negatives.
📍 Benefits of avoiding regressions
Let's quickly see the benefits that I consider important and that are visible quickly when we put into practice tests that avoid regressions:
Simplification of modifications and restructuring: With a wide range of unit tests, developers can carry out code changes and restructurings with greater confidence, knowing that the tests will notify them if any existing functionality is affected.
Reinforcement of product reliability: A comprehensive series of successful unit tests increases the credibility of the software, both for developers and stakeholders, by proving that the product works as intended.
Improved maintainability: Properly written and updated unit tests simplify the software maintenance process, as they help to quickly identify the consequences of code changes and ensure that functionality is not impaired.
Facilitation of integration: Quality unit tests facilitate the incorporation of new features or components, ensuring that modifications do not negatively impact pre-existing software.
I could list others, but the reading is already quite large, so I'll stop here! 😅
📍 Conclusion
In conclusion, maintaining the value of testing is crucial to ensuring continuous improvement and stability of software applications. Regressions pose a significant threat to software quality as they can reintroduce previously resolved problems or create new ones. To keep the tests valuable and avoid regressions, it is essential to adopt practices such as full code reviews, regular testing, automated test suites and effective communication between team members and always try to create more comprehensive tests that look for bugs. Stay alert! We need to contribute to the creation of reliable, high-quality software that meets the growing needs and expectations of users. Remember, the key to success is being proactive, adaptive, and diligent in our efforts to prevent regressions and maintain the integrity of our software. By following some tips and always keeping an eye out and, mainly, consuming content on the subject regularly, we will all be able to contribute to the improvement of the software and its functionalities!
I hope that you enjoyed it! Thank you so much for reading until the end, I hope the tips can help in everyday life! Until the next article! 😄🖐️
Books that I consider essential for everyone ✅:
Effective Software Testing: A Developer's Guide - by Mauricio Aniche
Unit Testing Principles, Practices, and Patterns - by Vladimir Khorikov



