Keeping tests valuable: Avoid implementation details!
The closer your tests are to the implementation the more sensitive they are to changes. - Mauricio Aniche.

Hi, I'm Rafael, but you can call me Rafa! 😄 I'm a software engineer passionate about everything that involves technology, with more than 5 years of experience in the market. Throughout my career, I worked in banking institutions, developing innovative solutions and contributing to the digital transformation of the financial sector.
With a strong interest in software architecture and testing, I am constantly looking to specialize and improve my skills in this area.
Here, you will find tips, tutorials and discussions on the most varied topics related to architecture, good practices and software testing, always with the aim of sharing knowledge and learning from other developers. I value the exchange of experiences and I am always willing to listen and learn from my professional colleagues.
Feel free to get in contact, leave your comments and share your own experiences and knowledge. Together, we can build a stronger, more collaborative community in the software development world.
Testing can be a common activity for thousands of developers. If the project you are working on does not have testing, I strongly recommend updating it as soon as possible. Testing is essential. But writing tests is a harder task than we think many. It can be easy at the beginning, but when the project grows and the business rules get more and more complex, maintaining those tests can be a big problem. In this post, we will better understand how tests should as much as possible be isolated from the implementation details of your code.
Understanding the problem
We often create unit tests that are too coupled to the inner workings of a class or method. This not only misses the point of a unit test but makes the class more difficult to refactor.
This happens a lot in the software industry. When we need to refactor a method or even the class, but we don't change the behavior of the class, tests usually fail! This is why many developers don't like tests! Because every time they need to look at the tests and do unnecessary maintenance since the behavior hasn't changed. When tests fail in this way, we call them false positive tests. What would this be?
What is a false positive test?
False Positive means that a test case fails while the code under test does not have the bug that the test is trying to detect, although in reality the functionality it covers works as expected. In this case, we can try to look for some problem that we may have inserted in the refactoring, so we look for a bug that does not exist. Even if we know that the behavior hasn't changed, software engineers are usually suspicious. But what some don't understand is that the problem is actually in the test! This happens because tests care about the implementation details that are in the code.
A false positive is a false alarm. The interesting thing is that even though it is a false alarm when it occurs we see clear signs that we need to improve our unit tests. To avoid this, we don't need to worry about testing the implementation details of a class or method that we are testing, but we should test whether the behaviors occur. Let's understand this better.
Do not write tests that leak implementation details
We have seen that a false positive when it occurs, indicates that the test failed, even though, in reality, the functionality it covers works as expected. We also saw that what can cause it most of the time is refactoring applied to the class or method. Let's now move on to a practical and common example, starting with the front-end, see the method below:
addItemToBasket(item: IProduct, quantity = 1) {
const itemToAdd: IBasketItem = this.mapProductItemToBasketItem(item, quantity);
let basket = this.basketSource.value;
if (basket === null) {
basket = this.createBasket();
}
basket.items = this.addOrUpdateItem(basket.items, itemToAdd, quantity);
this.setBasket(basket);
}
Now see the unit test:
it('should create a new basket if getCurrentBasketValue is null', () => {
service.basket$ = null;
service.addItemToBasket(mockItem);
const req = httpMock.expectOne(`${service.baseUrl}basket`);
expect(req.request.method).toBe('POST');
expect(service.getCurrentBasketValue).not.toBeNull();
});
The context is a class that creates a shopping cart and sends this information of the cart Id and also the number of items and quantity of each item in that cart to a Redis database. But what do we see strange in this test? In the beginning, see the basket$ = null attribute. Do we need to indicate that this variable is null? If there is a refactoring of the name of this attribute or even of how it is initialized, will the tests still pass? Probably not!
Why did the developer who created this test insert this variable? Maybe he thought he should ensure that the variable always initializes to null, but if he looks at what is being tested, which in this test is the addItemToBasket method, he will see that there is no such need! Also, the code implementation of the basket$ property is not important for this test method! Therefore this test leaks the details of the class implementation, which are not needed to test the behavior! Now take a look at this test line:
expect(service.getCurrentBasketValue).not.toBeNull();
Is this assertion necessary? If you look at the implementation of the method, you will notice that it only fetches the current state of the cart. We are not testing the current state of the cart at the moment, but only the flow of the addItemToBasket method. We don't need to know if BasketValue is null or not, because the first behavior tested is that if a cart doesn't exist, it should be created. That alone is what we want to test. So if you remove that line and leave the test as you will see below, the tests will keep passing:
it('should create a new basket', () => {
service.addItemToBasket(mockItem);
const req = httpMock.expectOne(`${service.baseUrl}basket`);
expect(req.request.method).toBe('POST');
});
New test:
it('should create a new basket', () => {
service.addItemToBasket(mockItem);
const req = httpMock.expectOne(`${service.baseUrl}basket`);
expect(req.request.method).toBe('POST');
});
What is the flow we are testing above? Take a look at the flow below:
If the basket is null, you should create a new one (
createBasket).The
createBasketthe method creates the new key/value in localStorage and returns the new cart.When the method creates a new cart the flow goes to
addOrUpdateItem, this method adds the new item to the array.Finally, the
setBasketmethod has the implementation responsible for sending the information via POST to the API.
See how the coverage of this method looks like in the coverage:
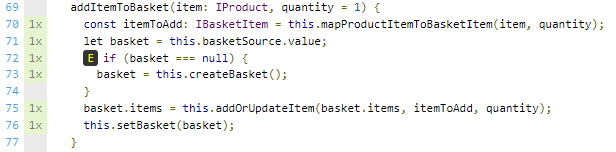
In this case, I am not testing the response of setBasket, because it is not the goal of the behavior of this method. The only thing I want to do in this test is to check whether the flow to a basket that does not exist happens or not. This test checks for this behavior and nothing else. We can have other tests that check if the behaviors occur as we expect. For example, I can run a separate test to simulate a response from the API, one case for success and another for errors. To simplify this test I have chosen not to introduce an expectation for a response, just the request is enough.
It is important to remember that the final flow of the addItemToBasket method is always to make a POST request to the API. If after a refactoring this behavior does not occur, your tests should fail, but now not for a false positive, because now the test is about specifically testing the behavior not the implementation details of the method or class.
I will make the code for this class available on my GitHub for you to browse and also perform tests on top of this class.
More examples of why to avoid!
Software Engineer and test specialist Mauricio Aniche comment something interesting in a post:
The closer your tests are to the implementation the more sensitive they are to changes.
Want to see more examples that prove this? Take a look at the code:
function multiply(x, y) {
let total = 0;
for (let i = 0; i < y; i++) {
total = add(total, x);
}
return total;
}
function add(total, quantity) {
return total + quantity;
}
Obvious that the code is too complex for its intended purpose, but this example makes it clear what we should pay attention to daily. Now take a look at the tests:
it('should call add function the correct number of times', () => {
spyOn(service, 'add').and.callThrough();
service.multiply(2, 2);
expect(service.add).toHaveBeenCalledTimes(2);
});
At first, the current implementation of the multiply method will work perfectly. The test will pass and the line in the coverage will turn green:

For some developers, this is enough. But as we have seen, these tests in the future are much more work than we think. Let's simplify the algorithm that does the multiply operation and see what happens with the tests:
multiply(x, y) {
return this.add(x, y);
}
add(total, quantity) {
return total * quantity; // change sum to multiply for this simple example
}
// TEST
it('should call add function the correct number of times', () => {
spyOn(service, 'add').and.callThrough();
service.multiply(2, 2);
expect(service.add).toHaveBeenCalledTimes(2);
});
Has the behavior of the method changed? No! It is still multiplying! But what about the implementation? It has changed a lot! So should the test fail or pass? The answer is easy, in this case, it will fail because the test is concerned with testing the details of the method implementation, not the behavior. The test was concerned with checking how many times the method was called, frankly, this is not necessary for this context! So this is what we have:

Now to conclude, let's change the test so that it focuses on behavior:
it('should multiply two numbers', () => {
expect(service.multiply(2, 3)).toEqual(6);
});
If one day the implementation is changed, we don't have to worry, because the behavior is what is being tested:
import * as math from 'mathjs';
multiply(x, y) {
return math.multiply(x, y);
}
// or just
multiply(x, y) {
return x * y;
}
Let's go to an example in the backend, where the context is of a system for HR. In large corporations you need some tools to filter employees based on different criteria like salary range, take a look at the code below:
public class EmployeeFinder {
public List<Employee> findEmployeesWithSalaryInRange(List<Employee> employeesToSearch, SalaryRange range) {
List<Employee> foundEmployees = new ArrayList<>();
for (Employee employee : employeesToSearch) {
if (employeeHasSalaryInRange(employee, range)) {
foundEmployees.add(employee);
}
}
return foundEmployees;
}
public boolean employeeHasSalaryInRange(Employee employee, SalaryRange range) {
return employee.getSalary() >= range.getMin() && employee.getSalary() <= range.getMax();
}
// other methods
}
Unit test:
public class EmployeeFinderTest {
private final Employee employeeOne = new Employee("One", 20_000);
private final Employee employeeTwo = new Employee("Two", 25_000);
private final Employee employeeThree = new Employee("Three", 30_000);
private final Employee employeeFour = new Employee("Four", 45_000);
private final List<Employee> employees = asList(employeeOne, employeeTwo, employeeThree, employeeFour);
private final EmployeeFinder employeeFinder = new EmployeeFinder();
@Test
public void test() {
List<Employee> actual = employeeFinder
.findEmployeesWithSalaryInRange(employees, new SalaryRange(27_000, 32_000));
assertThat(actual, is(sameBeanAs(asList(employeeThree))));
}
@Test
public void testGreaterThanMinimum() {
assertTrue(employeeFinder.employeeHasSalaryInRange(employeeTwo, new SalaryRange(25_000, 50_000)));
}
@Test
public void testLowerThanMaximum() {
assertTrue(employeeFinder.employeeHasSalaryInRange(employeeThree, new SalaryRange(10_000, 30_000)));
}
}
These tests have a lot of problems! From the description to the code design. Bad decisions were made. But I would like to focus on the theme of this post, do we test implementation or behavior? For this class, it is clear that we test its implementations! Why? If you look closely, there are two tests for the method employeeHasSalaryInRange that always expect the same output and their flow is part of the logic of the method findEmployeesWithSalaryInRange, they just allocated the logic to employeeHasSalaryInRange. Furthermore, we see that there is no need to allow employeeHasSalaryInRange to be public! The decision to make it public doesn't make sense because the method under test is already public, employeeHasSalaryInRange is only an auxiliary. Besides, testing this method just leaks implementation details that we don't want to know!
All tests should call only the method findEmployeesWithSalaryInRange. I don't care if this method has logic extracted into a private method, if it is using static methods from some other class, or if it is using third-party libraries, it is not relevant. The method must return employees with salaries in the requested range.
Now take a look at this adjusted testing only expected behavior:
import org.junit.Test;
import java.util.List;
import static com.shazam.shazamcrest.MatcherAssert.assertThat;
import static com.shazam.shazamcrest.matcher.Matchers.sameBeanAs;
import static java.util.Arrays.asList;
import static org.hamcrest.CoreMatchers.is;
@Test
public void findsEmployeesWithSalaryGreaterThanMinimum() {
List<Employee> actual = employeeFinder.findEmployeesWithSalaryInRange(employees, new SalaryRange(25_000, 50_000));
assertThat(actual, is(sameBeanAs(asList(employeeTwo, employeeThree, employeeFour))));
}
@Test
public void findsEmployeesWithSalaryLowerThanMaximum() {
List<Employee> actual = employeeFinder.findEmployeesWithSalaryInRange(employees, new SalaryRange(10_000, 30_000));
assertThat(actual, is(sameBeanAs(asList(employeeOne, employeeTwo, employeeThree))));
}
See that the tests are concerned with input and output. We don't test the details of the method, only the behavior.
Why testing implementation details is a bad idea?
The clear answer is that we developers see software with a different view than outsiders. Users see only a product. If we test implementation details, we may not check the behavior of the product. Developers need to keep this fixed in mind when testing. If every test we create tests the details, our tests will always need a lot of fixes with every new requirement that comes in! And it will be exhausting to accomplish this.
Another factor that has a big bearing on why we don't test the details of the code is the risk of change, we may have to frequently change constructs or parameters in tests. Any developer who has been through this experience knows how difficult it is to maintain and read the tests. In the example of this post there was only one test, imagine hundreds or thousands of tests!
Finally, testing implementations waste a lot of time! We should have tests that can provide quick feedback. That requires a few changes to assess how well we are still doing with our product. This will enable faster deployments and more confidence in our implementations. Everything we've read so far proves one thing we've already commented on. Most of the tests we write are unfortunately fragile to refactorings. I also know that I need to improve how I write my tests. Why? In the long run, having too many fragile tests is the same as having no tests at all: the cost of introducing new features becomes expensive and the overall quality of the project drops, compromising its long-term sustainability. Tests start to get messy and large, always costing a lot of time to adjust.
Maintain behavioral tests looking to validate your requirements.
In another article, Keeping tests valuable: Avoid common mistakes, I mentioned that we should test whether the requirements are being fulfilled. I continue with the same thought, requirements express the behaviors of the software. The example I showed in this article is of a login form and the requirements that are being tested are five:
must be a valid email address
must contain a special character @
must not contain a special character @ in initial
must not allow the local part of the email to contain more than 64 characters
See the tests:
it('should return false if local-part to be longer than 64 characters', () => {
let email = 'm'.repeat(65) + '@gmail.com';
component.form.controls['email'].setValue(email);
const result = component.form.controls['email'].valid;
expect(result).toBeFalse()
})
it('should return true if local part is less than 64 characters', () => {
let email = 'm'.repeat(64) + '@gmail.com';
component.form.controls['email'].setValue(email);
const result = component.form.controls['email'].valid;
expect(result).toBeTrue()
})
it('should return true if contain a special character @', () => {
const email = 'rafael@gmail.com'
component.form.controls['email'].setValue(email);
const result = component.form.controls['email'].valid;
expect(result).toBeTrue()
})
it('should return false if not contain a special character @', () => {
const email = 'rafael.gmail.com'
component.form.controls['email'].setValue(email);
const result = component.form.controls['email'].valid;
expect(result).toBeFalse()
})
it('should return false if email start with the @ special character', () => {
const email = '@t@gmail.com'
component.form.controls['email'].setValue(email);
const result = component.form.controls['email'].valid;
expect(result).toBeFalse()
})
Let's check whether we test behavior or implementation. We will refactor the code and change the validators:
//before
email: [null, [Validators.required, Validators.email]],
//after refactoring
email: [null, [Validators.required, Validators.pattern('[a-z0-9._%+-]+@[a-z0-9.-]+\\.[a-z]{2,4}$')]]
Take a good look at this refactoring and think about it. Is this change concerned with maintaining the requirements, i.e. the behavior? Let's let the Jasmine results tell us:
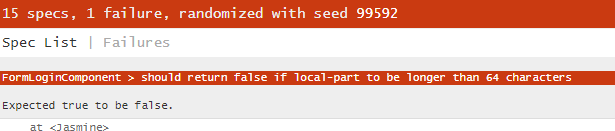
Let's look at the test that failed:
it('should return false if local-part to be longer than 64 characters', () => {
const email = 'm'.repeat(65) + '@gmail.com';
component.form.controls['email'].setValue(email);
const result = component.form.controls['email'].valid;
expect(result).toBeFalse()
})
The problem is that the additional regex expression does not care about the local part of an email address, there is no such validation anymore, so the requirement is not fulfilled. The refactoring then failed! It did not follow the requirements and so we have a test failure. In this specific case when testing a form and its behaviors, inputs and outputs, we should always keep in mind the behaviors. See that it is very common in applications using Angular, to see reactive forms, their fields will normally have validations, even if basic. I don't see implementation details in these tests, because when we adhere to Reactive Forms, we are already committing to use this same form pattern for the rest of the application components that may need forms.
But perhaps we continue to have questions, for example, are we leaking implementation details by inserting form.controls['email'] in these tests? The answer is no in this context. The first reason is that in this demo application, it is very basic validations that occur, there are no visual messages to give feedback to the end user, such as an invalid email. In this case, we want to test the behavior of this input to validate the requirements in a specific field e-mail. To be able to do that in this specific case we have to expose** form.controls. But we can use other strategies as the application grows, normally we would display feedback messages to the user pointing out the requirements of a valid email, these messages can be error messages for example:
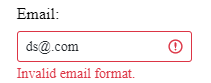
In this case, we don't have messages, but as we add new features, we could test if email input is invalid, it should display the error message specific to that invalid email. An interesting way to accomplish this is by using testing-library in Angular. At the moment I'm not going to go deeper into the testing library, maybe this will be for another post. But look what an interesting description the official site of the testing lib presents to us:

If you want to further avoid details like forms.controls, this solution using testing-library can help you a lot.
See an example described in the lib documentation:
import {render, screen, fireEvent} from '@testing-library/angular'
import {CounterComponent} from './counter.component.ts'
describe('Counter', () => {
test('should render counter', async () => {
await render(CounterComponent, {
componentProperties: {counter: 5},
})
expect(screen.getByText('Current Count: 5')).toBeInTheDocument()
})
test('should increment the counter on click', async () => {
await render(CounterComponent, {
componentProperties: {counter: 5},
})
fireEvent.click(screen.getByText('+'))
expect(screen.getByText('Current Count: 6')).toBeInTheDocument()
})
})
Well if that's not enough, I'll also leave a brief example of how a validation test of an email field and its possible input and output messages occurs, it's just an example, it's not something taken from projects that are in production, but the test uses Jest and Testing-Library together within the Angular framework:
const setup = async () => {
await render(SignUpComponent, {
imports: [HttpClientModule, SharedModule, ReactiveFormsModule],
});
};
describe('Validation', () => {
it.each`
label | inputValue | message
${'E-mail'} | ${'{space}{backspace}'} | ${'E-mail is required'}
${'E-mail'} | ${'wrong-format'} | ${'Invalid e-mail address'}
`(
'displays $message when $label has the value "$inputValue"',
async ({ label, inputValue, message }) => {
await setup();
expect(screen.queryByText(message)).not.toBeInTheDocument();
const input = screen.getByLabelText(label);
await userEvent.type(input, inputValue);
await userEvent.tab();
const errorMessage = await screen.findByText(message);
expect(errorMessage).toBeInTheDocument();
}
);
});
The approach used is very clean in terms of not bringing in implementation code. The test description is focused on email validation behaviors, note that we use Jest and testing-library methods together. Also if you pay attention we see that the error messages that the user will see if an email is invalid are being tested, i.e. the behaviors are being tested!
const errorMessage = await screen.findByText(message);
expect(errorMessage).toBeInTheDocument();
You may not like this approach of using Jest's it.each function, you may be thinking that in this case, we can separate each test. Indeed we can separate them into single it. But take a look at the description of the it.each function:
This approach with the testing-library is increasingly being adhered to. Each project has its pattern. But the important thing to note is that we can simply insert invalid inputs into our application and wait for expected outputs, which in this case of email validation, are the error messages that the end user will see, so we get closer and closer to what the user sees in terms of behavior in our application.
Maybe everything you have read so far, you are also questioning: "Most validations should be done in the backend, in the API". Yes, and you are right, but many large projects require many validations in the front-end as well, to minimize the chances of a user sending invalid inputs to the backend. I have worked with forms and rules on screens that contained very complex behaviors. This example of the form, the e-mail validation, does not even come close to the behaviors required for the clients I have worked with. It was mandatory that the validations also occur on the front-end. Many of these behaviors were not tested correctly, which generated bugs and dissatisfaction among the clients that owned the digital product.
My goal in showing some strategies that we can adopt in testing is to show that everything will depend on the current state that the project is in. You may be in a context where the tests use form.controls to validate behaviors. But it could be that your frontend application uses testing-library from the beginning. It could be that you use Jasmine, but you validate the behaviors based on the HTML outputs and the messages that the user will see at the end as well. The recommendation is that you focus on observable behavior. If input A is invalid, behavior X should occur. That is the focus of this post!
To conclude
Over the years in software development, you will understand that not everything is so simple. The same is true for testing. Writing good tests requires dedication, study and collaboration, especially collaboration when you are in teams with dozens or hundreds of programmers. Keeping tests valuable can save time for teams. Working hard to have valuable tests may take us out of our comfort zone for a while, but it brings us valuable professional gains for our careers. So the incentive is to continue to read, study and practice testing. I continue on this journey and have learned a lot throughout this year and hope to continue learning more and more!
I hope something was useful and if not, please post constructive criticism, this is the only way I can improve this post and others as well. Thank you for reading and see you next time.
References:
Good Code, Bad Code: Think like a software engineer - by Tom Long
Effective Software Testing: A developer's guide - by Mauricio Aniche
Unit Testing Principles, Practices, and Patterns - by Vladimir Khorikov
Testing Implementation Details - Kent C. Dodds




